Software development final exam answers: Part 2
These are the answers, along with some commentary, for part 2 (Computer Architecture and Operating Systems) of my software development final exam.Each question was graded out of 5, with points awarded for different parts of each question as described below; in some cases I awarded partial marks (e.g., 2 of 3 possible marks for part of a question) when someone had the right general idea but missed some details.
Computer Architecture and Operating Systems
-
Question: Name and describe the four states in MESI cache coherence.
Answer: The four states are "Modified", "Exclusive", "Shared", and "Invalid". In the "Modified" state, a cache line holds data which has been modified and must be written back to main memory before the cache line is invalidated or the memory location is read by another cache; no other caches may hold the same data. In the "Exclusive" state, the data matches what is stored in main memory and it is guaranteed that no other caches hold copies of the same data; this cache line can transition into the Modified state without any bus traffic. In the "Shared" state, the data matches what is stored in main memory but it is possible that other caches hold copies of the same data; if the cache line is written to, it must be first invalidated in other caches. In the "Invalid" state, the cache line is not valid and its contents is ignored (this is the state all cache lines start in when the CPU is first powered up).
Grading: I awarded 1 mark for getting the names right and 1 mark for each of the states correctly described (even if their names were wrong or absent).
Commentary: The average score on this question was 0.9/5, which I found disappointingly low. 75% of respondents received a score of zero, in most cases due to not even attempting the question.
A few people answered the question without any apparent hesistation, but the majority of those who responded clearly did not know the answer but instead figured it out. This is what I was hoping for, and why I phrased the question as I did: Saying "the four states in MESI cache coherence" was a cue (which several people picked up on) that people should be looking for states with names starting with the letters "M", "E", "S", and "I".
This question was, more than anything else, a test of whether people understood caches and cache coherence enough to invent a cache coherence protocol — because if you try, you end up with something similar to MESI pretty quickly. Understanding caches and coherence is very important for code performance: False sharing, for example, can cause a dramatic increase in bus traffic, and corresponding reduction in performance, if two separate threads access memory locations which are close to each other.
-
Question: Which of the following two functions is faster, and why?
Assume that the C code is translated into machine code in the obvious
manner, without optimization.
void zeroarray1(double * A) { int i, j; for (i = 0; i < 1024; i++) for (j = 0; j < 1024; j++) A[i * 1024 + j] = 0.0; } void zeroarray2(double * A) { int i, j; for (j = 0; j < 1024; j++) for (i = 0; i < 1024; i++) A[i * 1024 + j] = 0.0; }Answer: The function zeroarray1 is faster, because it accesses memory in sequential locations; this both reduces bus traffic, since each cache line is only loaded and stored once (in zeroarray2, the first cache line will almost certainly be evicted before we come around to j=1, i=0 and try to access it again) and on modern CPUs allows for automatic prefetching to occur.
Grading: I awarded 2 marks for getting the right answer; 2 marks for pointing out that it was because sequential memory accesses were better for caching; and 1 mark for giving a reason why sequential memory accesses helped for caching.
Commentary: The average score on this question was 4.5/5; about 75% of people scored 5/5, and a large number of people scored 4/5 and could probably have made it 5/5 by writing a few more words. (A few of the people scoring 4/5, however, admitted that they knew that sequential memory accesses were better for caches, but weren't sure why.)
To quote Phil Karlton, there are only two hard things in Computer Science: cache invalidation and naming things. (Some people add "and off-by-one errors!" to this.) I didn't ask any questions about naming things on this exam, but understanding caches is absolutely vital, and I couldn't let this test go without having one straightforward cache question.
Despite the high marks on this question, it revealed a surprising amount of confusion: Some people imagined cache lines as small as 4 bytes, while others thought the CPU cached entire 4 kB pages at a time. (In fact, there is a cache which deals with pages, but that's the TLB — used for paging table lookups — not the data cache.) Conversely, the "double" type — which I picked on the assumption that as an IEEE 754 standard data type, it would be widely understood — was believed to be as small as 1 byte in size and as large as 16 bytes. Nevertheless, since these were not relevant to the key point of the question — memory access patterns — I did not deduct marks for them.
-
Question: Explain the difference between a mutex and a read-write lock.
Answer: A mutex, or MUTual EXclusion lock, can only be "owned" by a single thread at once; if another thread wants the lock, it has to wait until the first thread releases it. A read-write lock — also known as a shared-exclusive lock, leading on occasion to the abbreviation "sex lock" — can be locked either for reading or for writing. If a thread holds a read-write lock for reading, then other threads can also obtain read locks; but if locked for writing, no locks (either reading or writing) can be obtained by other threads.
Grading: I awarded 2 marks for describing a mutex and 3 marks for describing a read-write lock.
Commentary: The average score on this question was 3.7/5; about two thirds of people scored 5/5 and a large minority of the rest scored 2/5.
Locking is an essential issue to understand, not just for operating system development, but also for any sort of multi-threaded programming, and understanding that there are multiple types of locking primitives is a very good thing. It's always possible to do without read-write locks — if nothing else, you can synthesize them out of mutexes — but being aware of them as a standard tool makes it far more likely that someone will recognize when they should be used.
-
Question: Why does the pthread_cond_wait function (wait on a condition
variable) take a locked mutex as a parameter?
Answer: The function atomically unlocks the mutex and puts the thread to sleep in order to avoid a race between the "waiting" thread and the "signalling" thread: Without the mutex, the "signalling" thread might send a wakeup signal after the "sleeping" thread checks the condition but before it goes to sleep; this would result in the wakeup signal getting lost (since nobody was listening for it) and the "sleeping" thread potentially sleeping indefinitely as a result.
Grading: This was simple: Either you got it, for 5 marks, or you didn't. To get the marks, I was looking for some understanding of exactly what would go wrong without the mutex.
Commentary: The average score on this question was 1.2/5; in other words, about a quarter of people got it.
This question was exceptional for the range of wrong answers provided; some of the repeated responses were that the mutex prevented multiple threads from sleeping on the condition variable at the same time (in fact, it's quite common for multiple "worker" threads to sleep on the same condition variable); that the mutex ensured that only one thread would wake up at once (in fact, POSIX provides separate pthread_cond_signal and pthread_cond_broadcast functions which wake up either one or all the sleeping threads); and that the ownership of the mutex would be transferred from the signalling thread to the sleeping thread as an optimization to avoid an unlock/lock pair (a clever idea, but not true; the wakeup functions don't take the mutex as a parameter).
I think this was the most important question on this part of the exam: If you don't understand caches you will end up writing slow code, but if you don't understand race conditions, you will can end up writing code which is broken — and not just broken in obvious ways, but broken in horribly subtle ways which will only bite you once in a blue moon and/or when you're getting the most traffic in your website's life and really really need for things to not break.
And before anyone objects that this is only relevant to multi-threaded programming: Race conditions are also responsible for many security bugs where a program races against an attacker, and come up very often when dealing with distributed systems — and sometimes the two overlap, as with a vulnerability which recently allowed over a million dollars to be stolen via ATMs.
-
Question: What is a TLB? When and why is it most often (completely) flushed?
Answer: A TLB is a Translation Lookaside (or Lookahead) Buffer; a cache of paging table entries. It is most often flushed when the operating system hands ownership of the CPU over to a new process, since different processes (usually) each have their own paging tables, and thus the values cached in the TLB are no longer correct copies of the paging tables in use.
Grading: I awarded 2 marks for describing what the TLB did (acronym expansion not required) and 3 marks for knowing that it was usually flushed during a context switch.
Commentary: The average score on this question was 2.9/5; over half of respondents received full marks.
The TLB is rarely mentioned in discussions about caching, but it is vitally important on modern systems. While I was looking for — and people provided — a discussion of data caches in question 2, I realized later that on many systems using standard 4 kB pages, the largest part of the penalty faced by zeroarray2 would be that each access would incur a TLB miss — not just requiring data to be read from main memory, but also requiring paging tables to be read and parsed.
The importance of TLBs to performance notwithstanding, it wasn't the main reason I included this question; rather, I decided to use it as a test for general understanding of virtual memory: If you know that paging tables are used to translate virtual addresses to physical addresses and that different processes have different paging tables, you've at least got the basics in place. Indeed, an earlier draft of this exam had the question "explain the difference between virtual and physical memory" — but I decided to replace it because it was too vague and likely to be hard to mark.
For this entire part, the average combined score was 13.2/25; approximately equal numbers of people received scores in each of the ranges 0-9, 10-12, 13-17, and 18-25.
I will be posting my answers, along with commentary, to part 3 of the exam — Mathematics — shortly after I finish marking the responses I have received to it.
A strange S3 performance anomaly
Tarsnap, my online backup service, stores data in Amazon S3 by synthesizing a log-structured filesystem out of S3 objects. This is a simple and very effective approach, but it has an interesting effect on Tarsnap's S3 access pattern: Most of its GETs are the result of log cleaning, and so while Tarsnap doesn't make a very large number of requests relative to the amount of data it has stored in S3 — backups are the classic "write once, read maybe" storage use case — it makes requests for a large number of distinct S3 objects. This makes Tarsnap quite sensitive to any S3 glitches which affect a small proportion of S3 objects.One such glitch happened earlier this week. The Tarsnap server code has a 3 second timeout for S3 GETs, and normally 99.7% of them complete within this window; the few which do not are usually due to transient network glitches or sluggish S3 endpoints, and usually succeed when they are retried. Between 2012-10-15 05:00 and 2012-10-16 10:00, however — a period of 27 hours — Tarsnap attempted to GET one particular S3 object 40 times, and every single attempt timed out. Clearly there was something unusual about that S3 object, but it wasn't anything I did -- that object was no larger than millions of other S3 objects Tarsnap has stored.
I'm guessing that what I saw here was an artifact of Amazon S3's replication process. S3 is documented as being able to "sustain the concurrent loss of data in two facilities", but Amazon does not state how this is achieved. The most obvious approach would be to have three copies of each S3 object residing in different datacenters, but this would result in a significant cost increase; a cheaper alternative which maintains the same "concurrent loss of two facilities" survivability criterion would be to utilize some form of erasure correction code: Given N+2 datacenters, take N equally-sized objects, apply a (N+2, N) code, and store each of the N+2 resulting parts in a different datacenter. While providing much cheaper storage, this does have one disadvantage: If the datacenter where a specific object was stored (they would presumably use a code which kept N objects intact and created two new "parity" objects) went offline (or its copy of the object was corrupted) then they would need to issue N reads to different datacenters in order to reconstruct that object — making that object read very much slower than normal.
Depending on price/performance considerations, this might not be the optimal strategy; I would not be surprised if they instead stored intact copies of each S3 object in two datacenters and only resorted to remote reads and erasure-correction reconstruction if both datacenters failed to satisfy the request. Whatever the precise implementation, based on my working assumption that Amazon has people who are at least as smart as I am — and given the performance anomaly I observed — I think it's quite likely that S3 uses some form of erasure-correction and as a result has a slow "data was almost but not quite lost" read path.
This raises two interesting points. First, the existence of such "black swan" objects changes the optimal retry behaviour. If there were merely "black swan" requests — that is, some small fraction of randomly selected requests are very slow — then a strategy of timing out quickly and re-issuing requests with the same timeout is optimal, since in such a case there's no reason to think that a request timing out once will make a retry more likely to time out. If the time needed for a request to complete is entirely determined by the object being read, on the other hand, there's no point timing out and retrying at all, since you'll only postpone the inevitable long wait. With both slow S3 objects and slow S3 hosts, a balanced approach is optimal — retries with increasingly long timeouts.
The second point is more subtle, but wider in its implications: The S3 SLA is meaningless. The S3 SLA provides for partial refunds in the event that S3 returns too many errors over a month — a 10% credit if more than 0.1% of requests fail, or a 25% credit if more than 1% of requests fail. However, no guarantee is provided concerning the time taken to return a response — and in a distributed system without response time guarantees, a crash failure is indistinguishable from (and thus must be treated the same as) a very slow response. Amazon could "cheat" the S3 SLA very easily by simply detecting outgoing InternalError and ServiceUnavailable responses, blocking them, and instead holding those TCP connections open without sending any response until the S3 client gives up.
Do I think Amazon is doing this? Not deliberately, to be sure — but I can't help noticing that whereas in 2008 I saw 0.3% of my GETs returning HTTP 500 or 503 responses and almost zero connection timeouts, I now see almost zero 500 or 503 responses but 0.3% of my GETs time out. Something happened within S3 which reduced the number of "failures" while lengthening the response-time tail; whether this was a good trade-off or not depends on how you're using S3.
Amazon is famously secretive, and I hate it. While I understand the reasoning of not wanting to share their "secret sauce" with competitors, I think it's ultimately futile; and as a user of Amazon Web Services, there have been plenty of times when knowing more about their internals could have allowed me to be a better customer. Sure, Amazon provides some assistance with such questions via their premium support, and it's quite possible that if I paid them $15,000/month they would have warned me that occasionally a few S3 objects will be persistently slow to access for a period of many hours; but to quote Jeff Bezos, even well-meaning gatekeepers slow innovation — so I firmly believe that the ecosystem of AWS users, and ultimately Amazon itself, would benefit from greater openness.
But for now, I'll keep watching my logs, trying to reverse-engineer the behaviour of Amazon's services, and adjusting my code based on my findings. And, of course, writing the occasional blog post about my observations.
Software development final exam answers: Part 1
These are the answers, along with some commentary, for part 1 (Algorithms and Data Structures) of my software development final exam.Each question was graded out of 5, with points awarded for different parts of each question as described below; in some cases I awarded partial marks (e.g., 2 of 3 possible marks for part of a question) when someone had the right general idea but missed some details.
Algorithms and Data Structures
-
Question: Is O(2^n) equal to O(3^n)? Why?
Answer: No. O(f(n)) = O(g(n)) if and only if f(n)/g(n) is bounded between two positive real numbers for all sufficiently large values of n; but as n increases, the ratio 2^n / 3^n tends to zero.
Grading: I awarded 2 marks for recognizing that these two sets of functions are not equal, and 3 marks for explaining why; for full marks, I wanted to see some mention of the limiting behaviour as n increases.
Commentary: The average score on this question was 2.8/5, which I found disappointingly low. Roughly a third of people thought that the two classes were equal, with the most common justification being that "we can ignore constants". While it is true that these both fall into the "exponential with linear exponent" class E, big-O notation is more precise and requires that functions are asymptotically within a constant multiplicative factor of each other.
A few people were confused by the notation, having seen "f(n) = O(g(n))" too many times; that is a misleading abuse of the "=" symbol, since it does not exhibit equivalence-relation behaviour. A better notation is "f(n) ∈ O(g(n))", since that makes it clear that O(g(n)) represents a set of functions.
I included this question as a test of whether people knew what big-O notation really means — in practice, it's very unlikely that anyone will need to compare O(2^n) and O(3^n) algorithms, but this made the two classes of functions obscure enough that people needed to rely on their understanding of big-O notation rather than memorized hierarchies.
-
Question: What is the expected run-time of quicksort? What is the
worst-case run-time?
Answer: The expected run-time of quicksort (for random inputs) is O(n log n). The worst-case run-time of quicksort is O(n^2).
Grading: I awarded 2 marks for the expected run-time and 3 marks for the worst-case run-time.
Commentary: The average score on this question was 4.8/5, which I found quite surprisingly high. I have seen many people use quicksort in situations where the worst case either occurs quite often or can be easily caused by an attacker to occur, so my hypothesis was that many software developers had forgotten about the poor worst-case behaviour; in fact, more people got the worst-case behaviour correct than the expected behaviour.
Some people pointed out that using a linear-time median-finding algorithm allows quicksort to have an improved worst-case; the observation was welcome but not necessary. A few people stated that the expected running time of quicksort was O(log n); I have no idea what sort of confusion would lead to this, unless perhaps it was simply a common typo.
-
Question: What is the difference between a binary tree [EDIT: that
should be binary search tree] and a B-tree? When and why does this
difference matter?
Answer: Internal nodes in a binary tree have at most two children, while internal nodes in a B-tree can have many children (depending on the block size). This is useful when the tree data is stored in a manner which exhibits large read latencies (e.g., on disk) since the higher fan-out means that the height of a B-tree is less than the height of a corresponding binary tree.
Grading: I awarded 2 marks for identifying that a B-tree can have more than 2 children per internal node; 2 marks for identifying that this makes B-trees faster on disk (or generally when access times are determined primarily by latency rather than bandwidth); and 1 mark for drawing the connection from having more children per internal node to having a smaller tree height. I awarded 1 mark to people who didn't mention that B-trees have an advantage on disk but instead mentioned that they are balanced (which not all binary search trees are); while this is true, the issue of balance alone should not cause someone to reach for a B-tree, since there are balanced binary trees (e.g., red-black trees) which are much simpler to implement than B-trees.
Commentary: The average score on this question was 3.2/5; most people knew that a B-tree had more children per internal node, but only half of respondents knew that this made them useful for data stored on disk. A sizeable number of people (including several who didn't know what exactly a B-tree was) remembered that B-trees were used by databases and filesystems but weren't sure why.
I included this question because I wanted to test not only whether people knew standard datastructures, but also whether people would be able to pick the right data structure for a task — and knowing when and why one datastructure is better than another is absolutely critical for that.
Marking this question brought to mind a common remark my mother — a former high school mathematics teacher, and IB examination marker — used to make: Answer the question asked. There were many people who explained what a B-tree is and when it's useful, but didn't explain why — and while in many cases I thought they probably knew the answer to that third part, I couldn't give marks for knowledge they didn't express.
-
Question:Name the heap operations used by heapsort and the asymptotic
running time of each.
Answer:There are two operations: Heapify, which takes n elements and builds a heap out of them in O(n) time; and pop-max, which deletes the largest element from the heap and returns it in O(log n) time.
Grading: I accepted a number of different formulations for heapsort and names for the functions. For the initial heap-building process, I awarded 3 marks for stating that the process took O(n) time, or 1 mark for saying that an element could be added in O(log n) time. I awarded 2 marks for stating that it took O(log n) time to remove the maximum (or minimum, in some formulations) element and make the necessary adjustments to retain the heap property.
Commentary: The average score on this question was 2.2/5; a large number of people couldn't remember what a heap was or how heapsort worked. I found this quite disappointing; while in most cases developers will want to use either quicksort or samplesort (if not concerned about worst-case behaviour) or mergesort, heaps are nonetheless a good data structure to know about for their relevance to priority queues.
Of those people who remembered about heapsort, a large majority did not know that a heap can be constructed in linear time. This is an important thing to know if you ever intend to use a heap: While it doesn't affect the asymptotic behaviour of heapsort (since extracting the elements still takes n log n time), it reduces the implicit constant; it can also be useful if you only want to extract a limited number of the largest elements.
A few people explained how linear-time heap construction works — by "building up" with progressively larger sub-heaps — which was welcome but not necessary.
-
Question:Describe an algorithm that determines if a graph is bipartite.
Answer: Attempt to 2-colour the graph as follows:
- Pick an uncoloured vertex; if there are none remaining, return success.
- Colour that vertex red.
- Perform a graph traversal (depth-first search and breadth-first search both work) starting from the vertex we picked. Every time we reach a vertex, colour it green if all its coloured neighbours are red, or red if all of its coloured neighbours are green; if it has both red and green neighbours, return failure.
- Go to step 1.
The graph is bipartite if and only if the 2-colouring algorithm did not fail.
Grading: I awarded 2 marks for showing an understanding of what "bipartite" meant (either by stating the definition, or by providing an algorithm which demonstrated that understanding). I awarded 3 marks for a correct algorithm; or 2 marks for an algorithm which worked only for connected graphs.
Commentary: The average score on this question was 2.3/5; this had the largest number of zero scores — from people who didn't know what a bipartite graph was — but of those who didn't score zero, most received either 4/5 or 5/5 (depending on whether they handled the case of disconnected graphs; the majority did not).
I decided to include this question in part because it is not something which many software developers are likely to have needed to know recently, and is not an algorithm which is often taught (it's too simple to cover in a graph theory course, but in a first algorithms course few instructors will want to spend time explaining what a bipartite graph is). As such, it acted as a test for whether people could invent an algorithm for a simple problem rather than merely reciting those they had learned in class.
I deliberately did not provide a definition for "bipartite", opting instead to use that as a rough measure for exposure (and recollection) of basic graph theory. One person admitted to consulting a dictionary and coming up with the (incorrect) definition that a bipartite graph had two connected components; I suspect he was not the only person who turned to a dictionary, since this was a common theme among those who did not know the correct definition.
For this entire part, the average combined score was 15.2/25; approximately equal numbers of people received scores in each of the ranges 0-9, 10-15, 16-21, and 22-25. The largest surprise to me was how long it took to mark each set of answers; even after selecting questions in part based on wanting to be able to mark them quickly, it took me many hours.
I will be posting my answers, along with commentary, to part 2 of the exam — Computer Architecture and Operating Systems — shortly after I finish marking the responses I have received to it.
Software development final exam: Part 4
This is the fourth and final part of my software development final exam. If you haven't read that introductory blog post, please go read it now.
Networking and systems
- What is a primary key?
- Describe the packets exchanged during the setup and teardown of a TCP connection.
- What is the difference between flow control and congestion control?
- Name and describe the four characteristics of ACID.
- What is an idempotent operation? Why are they important in distributed systems?
If you would like me to grade your answers, please send an email to cperciva-exam-part4@tarsnap.com with your answers to the above questions along with the following two:
- Do you have a degree in a computing-related field? (If yes, from which institution?)
- Are you employed as a software developer?
Please note that the questions are intended to be answered under "exam conditions", i.e., without discussion with anyone else, and without consulting Google, Wikipedia, or other sources. I'm running this as an experiment to see how much basic computer science software developers know, and in what areas, so please don't "cheat".
I will be posting the answers along with an analysis of the responses I have received next week. My apologies to people who are still waiting for me to grade their answers — it's taking longer than I expected.
Software development final exam: Part 3
This is part 3 of my software development final exam. If you haven't read that introductory blog post, please go read it now.
Mathematics
- You have a spam filter which marks 99% of spam messages as spam, and 99% of non-spam messages as non-spam (and gets the other 1% wrong). 95% of the email arriving at your server is spam. What fraction of messages in your inbox are spam? What fraction of messages in your spam folder are not spam?
- What is the difference between a hash function [EDIT: make that a cryptographic hash function] and a message authentication code?
-
Define
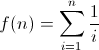
Find
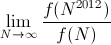
Show work — a formal proof is not required, but I'd like to see more than just the answer. (2-3 sentences is probably about right.) - You are testing two different versions of a website (A and B) to determine which one yields a higher sign-up rate. You know that if version B is 10% more effective than version A, then once N visitors have reached your site there is a 90% chance that version B will have produced more signups than version A. Approximately how many visitors would you need in order to have that same 90% chance, if version B is instead only 5% more effective than version A?
- Why should a message be "padded" (and not just with zeroes) before being encrypted or signed using RSA?
If you would like me to grade your answers, please send an email to cperciva-exam-part3@tarsnap.com with your answers to the above questions along with the following two:
- Do you have a degree in a computing-related field? (If yes, from which institution?)
- Are you employed as a software developer?
Please note that the questions are intended to be answered under "exam conditions", i.e., without discussion with anyone else, and without consulting Google, Wikipedia, or other sources. I'm running this as an experiment to see how much basic computer science software developers know, and in what areas, so please don't "cheat".
Part 4 of the exam — networking and systems — is now available.
Software development final exam: Part 2
This is part 2 of my software development final exam. If you haven't read that introductory blog post, please go read it now.
Computer Architecture and Operating Systems
- Name and describe the four states in MESI cache coherence.
-
Which of the following two functions is faster, and why? Assume that
the C code is translated into machine code in the obvious manner, without
optimization.
void zeroarray1(double * A) { int i, j; for (i = 0; i < 1024; i++) for (j = 0; j < 1024; j++) A[i * 1024 + j] = 0.0; } void zeroarray2(double * A) { int i, j; for (j = 0; j < 1024; j++) for (i = 0; i < 1024; i++) A[i * 1024 + j] = 0.0; } - Explain the difference between a mutex and a read-write lock.
- Why does the pthread_cond_wait function (wait on a condition variable) take a locked mutex as a parameter?
- What is a TLB? When and why is it most often (completely) flushed?
If you would like me to grade your answers, please send an email to cperciva-exam-part2@tarsnap.com with your answers to the above questions along with the following two:
- Do you have a degree in a computing-related field? (If yes, from which institution?)
- Are you employed as a software developer?
Please note that the questions are intended to be answered under "exam conditions", i.e., without discussion with anyone else, and without consulting Google, Wikipedia, or other sources. I'm running this as an experiment to see how much basic computer science software developers know, and in what areas, so please don't "cheat".
Part 3 of the exam — mathematics — is now available.
Software development final exam: Part 1
This is part 1 of my software development final exam. If you haven't read that introductory blog post, please go read it now.
Algorithms and Data Structures
- Is O(2^n) equal to O(3^n)? Why?
- What is the expected run-time of quicksort? What is the worst-case run-time?
- What is the difference between a binary tree [EDIT: that should be binary search tree] and a B-tree? When and why does this difference matter?
- Name the heap operations used by heapsort and the asymptotic running time of each.
- Describe an algorithm that determines if a graph is bipartite.
If you would like me to grade your answers, please send an email to
cperciva-exam-part1@tarsnap.com [EDIT: I have now
finished marking part 1 answers; please do not send me any more] with your
answers to the above questions along with the following two:
- Do you have a degree in a computing-related field? (If yes, from which institution?)
- Are you employed as a software developer?
Please note that the questions are intended to be answered under "exam conditions", i.e., without discussion with anyone else, and without consulting Google, Wikipedia, or other sources. I'm running this as an experiment to see how much basic computer science software developers know, and in what areas, so please don't "cheat".
Part 2 of the exam — computer architecture and operating systems — is now available.
The software development final exam
When I tell North Americans about my time at Oxford University, one aspect of its undergraduate program inevitably surprises them: Final examinations. Rather than writing examinations at the end of each term, students in most subjects write a single set of examinations at the end of their final year, on which their entire degree performance is measured. (In recent years, some subjects have switched to annual examinations.) As terrifying as this might sound, the system has some merits: Whereas many students at institutions with termly examinations study the day before an exam and forget the material the day after the exam, attempting to "cram" three years worth of material at once is largely an exercise in futility; as such, Oxford's examinations often provide a better measure of how much material a student has learned and retained. Given some of the conversations I've had with — and code I've seen from — people who have received computer science degrees from major universities and are actively working as software developers, I think that last part is very important: There's a lot of people out there who have forgotten some very basic — and very important — material.As an experiment, I've put together a "software development final exam", consisting of 20 questions split into four "papers" of five questions each. The questions vary in difficulty, but any good undergraduate program in computer science should cover all the material needed to answer these questions; and on each paper, at least four of the five questions relates directly to material I have needed to know during my time working on Tarsnap, so these are not simply theoretical questions. If you can't answer the majority of the questions on these four papers, and you're working or intend to work as a software developer, you should ask yourself why — most likely you're either you're missing something you really should know, or you're lucky enough to be working within a narrow area where your deficit doesn't matter. Conversely, if you can answer all of the questions, you're probably in good shape — while a 20 question exam obviously can't cover every topic in a three or four year degree, I think I've covered a wide enough range that it's unlikely anyone could answer every question correctly while still having any serious deficit in their basic computer science knowledge.
One thing I have not included is any test of practical programming ability — FizzBuzz, reversing a linked list, or suchlike; there are two reasons for this exclusion. First, there's a wide variety of languages out there, and some questions are easier or harder — or just plain don't make sense — in different languages. Second, I wanted questions which are easy to mark as right or wrong — both to benefit people who want to use these questions to evaluate their own knowledge, and also because I will be offering to grade any responses I receive. And I would like to receive responses: My readership may be a biased sample, but a sample it is nonetheless, and I'd love to see both how people do overall and any patterns I can find within the data.
The four papers — which will be linked as I post them over the next four days — are:
- Algorithms and Data Structures
- Computer Architecture and Operating Systems
- Mathematics
- Networking and Systems
Thanks to Slava, Colin, Graham, Angela, and Eitan for discussions over the past two years which led to this exam and for allowing me to throw questions at them and watch their thought processes.
FreeBSD/EC2 update
The FreeBSD 9.1 release process is taking a bit longer than we hoped for; but six weeks after 9.1-RC1, FreeBSD 9.1-RC2 is now on its way out to the FreeBSD mirror network — I imagine that Ken will send out an email officially announcing its avaiability on Monday. As usual, I have built some EC2 AMIs for this release candidate; and I took the opportunity to make some changes in how the AMIs work.Most importantly, starting with FreeBSD 9.1-RC2 you will need to SSH in as "ec2-user". I've never been very happy with opening up SSH to root, and it seems that "ec2-user" is as much of a standard account name as anything. Once logged in, you can su to root, of course — there's no password set in the AMI.
The other change I made was in how I built the disk image. Until now, I was taking a standard "build from source code" approach — build everything, then make distrib-dirs distribution installworld installkernel. I've now switched over to using bits from the published ISO: I install the "base", "games", "doc", and (on amd64) "lib32" bits from the ISO, and the only part I build myself and install into the image is the (patched) FreeBSD kernel. This has very little user-visible impact (probably the only change anyone will ever see from this is that 'freebsd-update IDS' doesn't complain about library files which are different due to internal timestamps) but gets me one step closer to my goal of an "all release bits" AMI.
If nobody reports any problems, this is what FreeBSD 9.1-RELEASE is going to look like when it is released in about 3 weeks. While I'd love to believe that everything is perfect, I'm sure there's going to be at least a few minor glitches lurking... so if you want a better 9.1-RELEASE, go forth and test!